从零写一个编译器(三)- simpleJava Compiler
2020-02-13
是时候来写真正的编译器了。
这并不是指一个simple的java compiler,而是一个名为simpleJava的语言的Compiler。
它会产生出合法的NASM代码,并交由NASM编译成.obj文件,最后由gcc链接成可执行文件。
不过在开始写这个编译器之前,由于我重写了Parser和Scanner,所以我认为有必要稍微简单说明一下新的结构。
新Parser & Scanner
在利用上上篇文章写好的Parser来计算SimpleJava的CFG的Action和Goto表时,竟然花费了接近5分钟的时间才算出来:
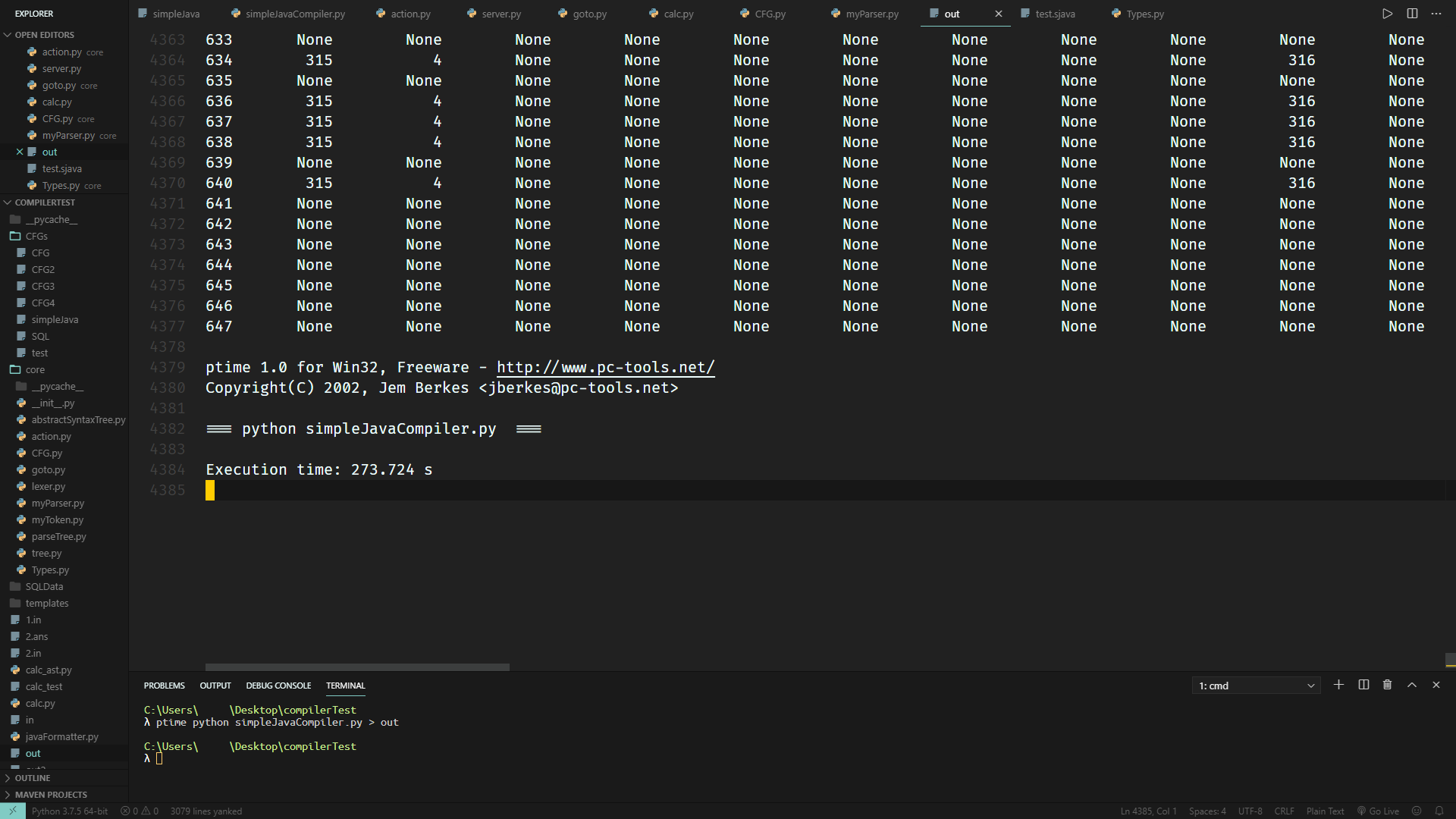
在设计CFG的早期阶段,引入任何一个新语法都可能导致CFG不再是LR(1)的。而引入新语法后,若真的不再是LR(1),则又要加以分析并且修改。如果每次修改都要花费5分钟才能算出来,那按照我这个急性子可能这辈子都改不出心目中理想的CFG了。
另外,在复习LR(1)的过程中,我发现了自己以前设计上的失误,以及非常多可以加以改进的部分。
所以,比起干等,不如直接重写一份前端,将性能优化到极致。
Scanner
之前使用Types.py来定义,有三个坏处:
- 所有的应用都要用同一个
Types.py文件来定义,非常容易造成混乱 - 用于CFG分析中的displayName需要额外手动利用一个字典进行维护,非常麻烦
- 类型定义居然要用一个python类,而不是文件来描述?
因此,我在新的Scanner中引入了TypeDefinition类,用于从文件中读取类型定义。每行定义一个类型,包含两个或三个元素(由两个空格分割),分别描述标准命名、匹配规则和显示命名。
有些不可能出现的元素,像是空格和注释,就不会有显示命名。因此只有两个元素。
另外,为了加速,所有的类型都会被映射成一个int。
根据上述描述,很容易写出新的代码。
接下来开始写Scanner。其实它就是Lexer,所以没什么好说的。不过这一次,我提供了根据传递进来的类型过滤列表对输出结果进行过滤的功能。这样也可以在更大程度上提供程序的灵活性:
import re
from typeDef import TypeDefinition
def parse(typeDef, src_code, filter_=None):
"""
return a list of Token object, generated by the input src_code
if want to filter out any type of token, use filter.
eg:
parse(typedef, src, ['block_comment', 'line_comment'])
"""
assert isinstance(typeDef, TypeDefinition)
result = []
token_regex = typeDef.getRE()
for mo in re.finditer(token_regex, src_code):
if filter_ is None or mo.lastgroup not in filter_:
id_ = typeDef.getID(mo.lastgroup)
result.append((str(mo[0]), id_))
result.append(("$", "$"))
return result
if __name__ == "__main__":
typedef = TypeDefinition.load("simpleJava/typedef")
with open("simpleJava/test.sjava", "r") as f:
src_code = f.read()
print(parse(typedef, src_code, ['space']))
Parser
首先来看看CFG的设计。与之前不同,终结符两边不用再用引号括起来了。这是基于一个简单的事实而作出的改动: 终结符不可能出现在产生式左边。 因此,只要记录一下出现在产生式左侧的符号,以及所有符号,就能算出来哪些是非终结符了。
其次,CFG类将会承载更多的数据。为了说明这一点,先把目光转到LRItem这里。
这一次我抛弃了Grammar和Production类、转而只使用LRItem来描述。这是因为显然没有必要把同一个non-terminal能够产生的产生式强行放到一起的必要。计算LRItemSet的闭包,显然是以LRItem作为基本单位的,而不用像之前那样把Production和Grammar拆分了之后组成临时元组来当作基本单元。
此外,LRItem也可以改用更简洁的实现。先来说明一下LRItem的构造:
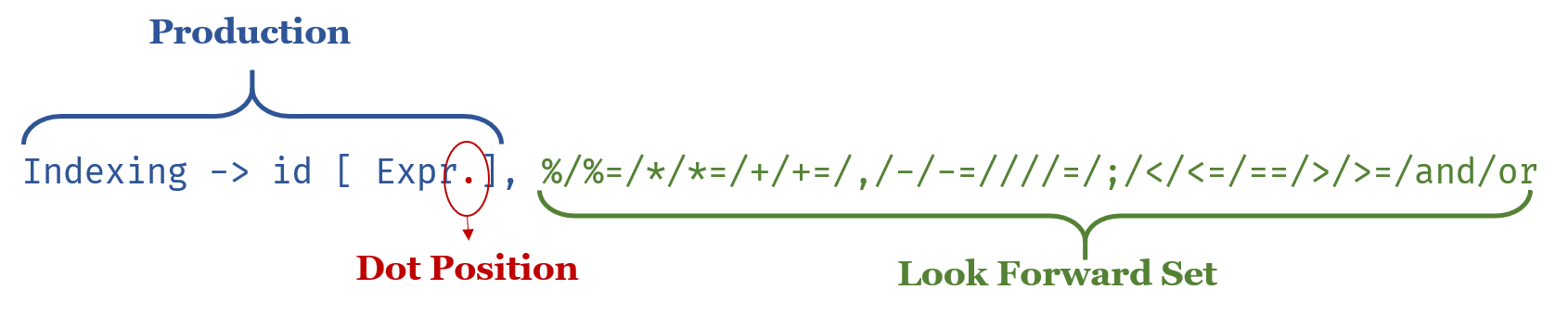
很容易发现的一点是,Production是不可能在运行过程中改变的。既然如此,那为什么不用一个编号来取代掉没用的元组呢? 这样,既能节省空间,也能让运行效率变得更快。
如此一来,LRItem本质上就是个三元组了: (int, int, set)。而最后的set里,也只是存了一堆数字而已。
相比原来,应该算是减少了相当多没用的内存占用了吧。
CFG
为了支持将Production映射到ID的功能,有必要让CFG存储这样的映射。同样,由于需要计算sequence的first,所以需要获取sequence,因此需要提供根据ID返回sequence的功能。还有,在计算LRItemSet的自动机的时候,需要获取next,而先返回sequence再由外部取值实在是太慢且太繁琐。因此最好提供一个功能,根据给定的ID和位置,返回对应产生式对应位置的元素。这样明确之后不难写出新的代码。
LRItem
接下来是LRItem的设计。
尽管已经尽可能地简化了存储的数据,要对这些数据进行计算哈希值依然比较慢。这是因为展望符集合的存在: set是mutable对象,不能直接求hash。因此需要根据展望符集合生成一个列表并对这个列表进行排序后才能算出真正的hash来。显然排序和生成列表都是相对比较浪费时间的,因此采用一个self.__hashVal的变量,存储哈希值。这样,每个LRItem的hash值只会被计算一次。
另外,为了效率,照理说lookForward应该用拷贝构造函数,按照self.lookForward = set(lookForward)生成一个新的set,确保内部的数据不会被外部修改。然而,为了效率,内部直接保存外部传进来的引用是最快的,可以避免相当多没有必要的构造。这样就带来了一个挑战: 确保展望符集合不会在外部被修改。
基于上述优化的实现在此。
LRItemSet
接下来考虑LRItemSet的设计。
鉴于LRItem已经包含了关于文法的全部信息,那么LRItemSet就真的只需要维护一个set就可以了。
话虽如此,还有不少可以改进的地方。首先,考虑到计算自动机时,LRItemSet经常需要计算hash。那么同样,可以仿照LRItem的方法,将hash值缓存下来,减少不必要的计算:
class LRItemSet:
def __init__(self, cfg):
# ...
self.__needRecalculateHash = True # lazy tag
self.__hashVal = None
def __hash__(self):
if self.__needRecalculateHash:
self.__hashVal = hash(tuple(sorted(list(self.items)))) # TIME COSTING
self.__needRecalculateHash = False
return self.__hashVal
另外,观察计算自动机时的BFS:
while que:
cur = que.popleft()
if cur not in itemToID:
itemToID[cur] = len(itemToID)
for step in cur.getNext():
nextItemSetCore = cur.goto(step, firstDict) # get the core first
getNext总是和goto联用。因此,我们可以在getNext中,记录一下step对应着哪些item:
def getNext(self):
"""
get all possible out-pointing edges toward other LRItemSets.
"""
result = set()
for item in self.items:
step = item.get()
if step is not None and step != "":
self.__map.setdefault(step, []).append(item)
result.add(step)
return result
这样,在获取goto的时候,可以避免多余的if item.getNext() == step这种判定。直接根据已经记录下来的映射关系,将这些item加进新的ItemSet里:
def goto(self, step):
"""
return a new LRItemSet.
"""
result = LRItemSet(self.cfg)
for item in self.__map[step]:
result.addItem(item.gotoNext())
return result
接下来来实现计算闭包。
为了避免再次出现上次那种还需要在updateClosure之后reduceForward的情况,这一次直接用(productionID, dotPos)作为键,建立一个字典,维护一个tuple -> set的映射,set中存储lookForward集合。
仍然是BFS,但是这一次,在下一个字符是non-terminal,因而需要计算下一个LRItem的时候,可以稍微加速一点。
首先不难发现,需要加进队列中的LRItem,是由两层for产生的:
- 遍历该non-terminal所能推导出的所有production
- 对于每个production,遍历所有可能出现的firstSet,将新production和firstSet组成新LRItem放入队列内。
这样,很容易注意到,我们可以预先计算出当前产生式+每个展望符所能产生的所有新产生式$\forall i, \textbf{T} \to \cdots, \beta_0 \beta_1 , ... , \beta_n \gamma_i$。进而,我们可以预先计算出每个新产生式对应的first集合。这样,对于下一个non-terminal所能推导出的所有production,我们就不必重复计算first集了。
此外,计算sequence的first本身是非常耗时的一件事情。因此,可以利用字典加速: 存储已经计算过的sequence的first,避免重复计算。同时,也可以尽可能地减少set的数量,减少创建对象所需分配内存的时间。配合LRItem直接存引用,可以剩下相当多的内存和时间。
根据上述改进,不难写出代码。
LRItemSet DFA
接下来考虑自动机的计算。
既然计算闭包是非常费时间的,而又总是要算出闭包后才能判断当前项目集是否已经存在,因此还是老样子,利用字典进行加速:
if nextItemSetCore not in coreToClosure:
coreToClosure[nextItemSetCore] = nextItemSetCore.calcClosure(firstDict)
nextItemSet = coreToClosure[nextItemSetCore]
计算goto的新核心是很快的。这样,将新核心映射到Closure的话,就可以将计算闭包的次数减少到$n$次。$n$代表该CFG对应的总状态数。
接下来的部分就几乎和之前没有任何区别了。代码请参阅这里。
到这里为止就没有什么再改进的必要了。同时也和之前写的ParseTree无缝对接上了,可喜可贺。在某种程度上也算是实现了模块化的设计吧。
进行了这么多用来加速的努力之后,来利用cProfile看一下结果吧!
首先是simpleJavaCompiler.py:
import ...
typedef = TypeDefinition.load("simpleJava/typedef")
cfg = ContextFreeGrammar.load(typedef, "simpleJava/simpleJavaCFG")
action, goto = Parser.genActionGoto(typedef, cfg)
action.save('simpleJava/simpleJavaAction')
goto.save('simpleJava/simpleJavaGoto')
exit()
然后是performanceProfiler.py:
import cProfile, pstats, io
from pstats import SortKey
with open("simpleJavaCompiler.py", "r") as f:
src = f.read()
cProfile.run(src)
结果如下:
2166025 function calls (2165652 primitive calls) in 1.110 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
...
143867 0.051 0.000 0.051 0.000 Parser.py:107(__init__)
50183 0.028 0.000 0.073 0.000 Parser.py:120(__hash__)
136771 0.048 0.000 0.124 0.000 Parser.py:144(get)
699 0.508 0.001 0.841 0.001 Parser.py:205(calcClosure)
79974 0.019 0.000 0.019 0.000 Parser.py:221(<listcomp>)
1 0.027 0.027 1.005 1.005 Parser.py:299(genActionGoto)
...
136771 0.067 0.000 0.076 0.000 cfg.py:82(get)
89771 0.013 0.000 0.013 0.000 cfg.py:97(getProduction)
...
269204 0.022 0.000 0.022 0.000 {method 'issubset' of 'set' objects}
141704 0.018 0.000 0.018 0.000 {method 'setdefault' of 'dict' objects}
...
注意到这一行:
699 0.508 0.001 0.841 0.001 Parser.py:205(calcClosure)
尽管做了那么多的努力,不过累计起来还是花掉了0.84秒用于计算闭包。可见,闭包的基础计算量真的相当大。
好在,相比之前647个状态算273.724秒,现在699个状态1.11秒就能算完,提升了266.417倍,也算是相当不错的成果了。
接下来就开始写真正的simpleJava吧。
语言设计
从名字就能看出来,这个语言是简化版的java。确实如此。
除了python之外,我最喜欢的语言就是java了。此外,我也觉得C++很不错。然而,它们都有一些我不喜欢的地方。
在java中,所有代码都必须放在public class ...内来书写。就算是最简单的hello world也要声明一个类:
public class Main {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}
我不喜欢这样。所以,我希望simpleJava能够像python那样,可以把语句直接写在文件中,当作脚本使用。另外,java中不能重载运算符,这让我觉得很难接受。
另外一方面,python不像java那样每个变量的类型都几乎可以完全确定,尽管灵活,却总给人一种模糊的感觉。我也不喜欢。此外,像是numpy这种非常重要的第三方库的命名规范实在是令人作呕。而java中,至少所有的类名都是规范的。
而C++,语言特性太多,不同的库有不同的使用风格,跟拥有pythonic一称的python着实相去甚远。此外,引用虽然强大,能够实现swap等,但是不用特地标出来真的会舒服很多。
因此,这多少算是python和java(可能还有C++)的混合体。
先来按照心目中的感觉,随便写一点代码。比方说,最大公约数,二分搜索:
int gcd(int a, int b) {
int temp;
while (b) {
temp = a % b;
a = b;
b = temp;
}
return b;
}
int binarySearch(int[] arr, int val) {
/**
* given the array and the value, returns
* the index of the val, or -1 if not found
*/
for (int l = 0, r = len(arr); l < r; ) {
int mid = l + ((r - l) >> 1);
if (arr[mid] == val) {
l = r = mid;
} else if (arr[mid] < val) {
mid = l + 1;
} else {
mid = r;
}
}
// assert l == r;
return arr[l] == val ? l : -1;
}
int n = int(input());
int[] arr = new int[n];
for (int i = 0; i < n; ++i) {
arr[i] = int(input());
}
int m = int(input());
for (int i = 0; i < m; ++i) {
int query = int(input());
result = binarySearch(arr, query);
if (result == -1) {
print("Key not found in array.");
} else {
print("Key found at " + str(query));
}
}
另外,我认为将&&换成and是个非常不错的改变。例如如下CF377A的c++解:
void dfs(int x, int y) {
if (!k) return;
for (int d = 0; d < 4; ++d) {
int nx = x + dx[d], ny = y + dy[d];
if (0 <= nx && nx < n && 0 <= ny && ny < m && maze[nx][ny] == '.' && !vis[nx][ny]) {
vis[nx][ny] = 1;
dfs(nx, ny);
vis[nx][ny] = 0;
}
}
if (!k) return;
maze[x][y] = 'X';
--k;
return;
}
其中用于判断是否可以dfs的条件,应该可以在simpleJava中改写成如下形式:
if (0 <= nx and 0 < n and 0 <= ny and ny < m and maze[nx][ny] == '.' and not vis[nx][ny]) {
// ...
}
几乎就是python的感觉了(笑)
-
关于指针
其实我有一段时间相当喜欢指针和引用。但是说实话,果然还是Java写起来爽啊。所以还是删掉指针吧。
-
关于下标
python、Java、C++都是从0开始,左闭右开,Dijkstra也曾说明过这样做的理由,正巧我也非常认同。因此下标毫无疑问是从0开始的。
-
关于切片
python的切片确实很爽,考虑之后加进去!
真正的CFG
既然名为真正的CFG,就说明必然和理想中的文法有出入----事实上确实如此。
文法在此。
很可惜,没能做到int[] arr;这样的语法,妥协成了int# arr;。
这是因为:
Type -> BasicType Arrays
BasicType -> id
Arrays -> Arrays [ ] | [ ]
和:
f1 -> f1 [ f2 ]
f2 -> Value
Value -> id
导致的。在BasicType -> id和Value -> id需要被规约的时候,后面都会跟着[。此时就会产生规约-规约冲突。
想着int* arr也不错的样子,但是*作为指针的观念已然根深蒂固,最后还是用个全新的符号表示数组吧。
建立AST
首先要确定不同的节点应该怎么排列它的子节点。为此,我画了不少示意图:

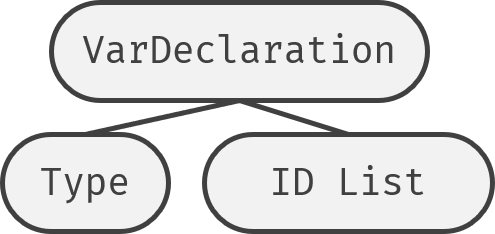
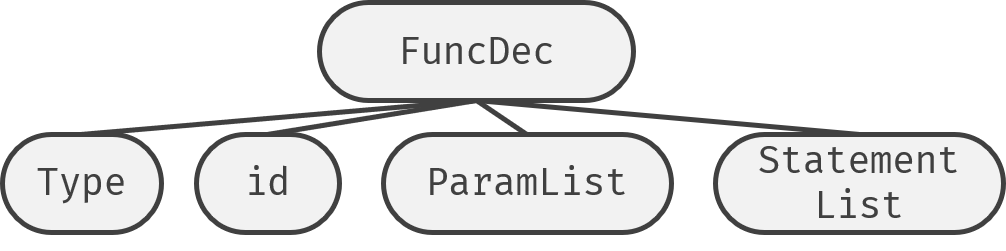


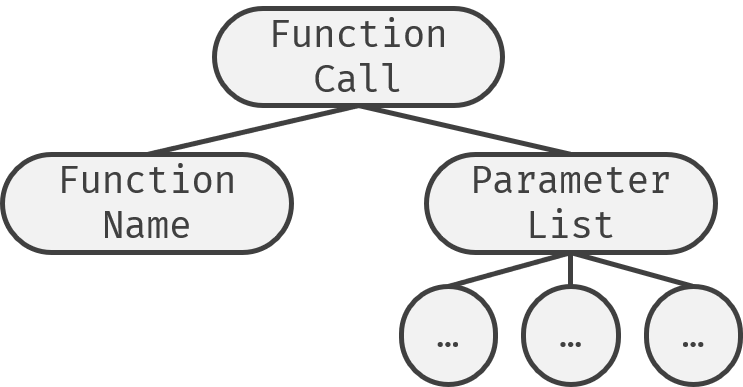
之后就是给parse Tree的每个产生式规定一个文法,用于产生AST了。
给每个产生式都写一个规则实在是太可怕了...大致350多行,贴在博客里简直就是毁灭文章观感和浏览器渲染器的最佳选择。如果感兴趣的话请参阅这里。
结果,大致上长这样:

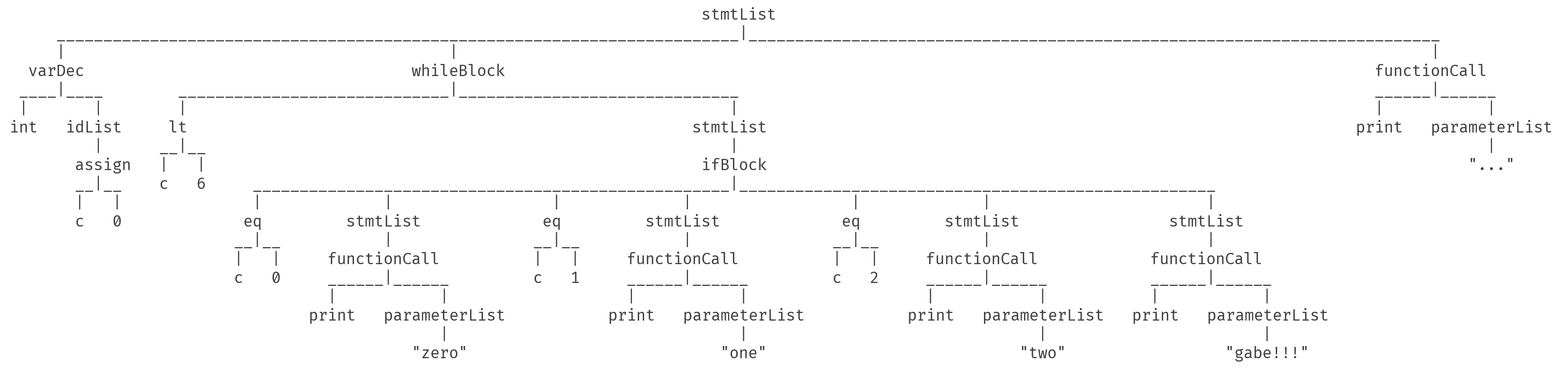
看起来非常庞大对吧? 然而相比之下,这已经比ParseTree不知道好到哪里去了...
NASM语法
接下来要开始考虑IR的设计,以及最终的Code Generation了。考虑到接下来的IR设计,像是TAC序列、Code Block、控制流图等,应当尽可能地以方便生成目标代码作为主要目的,因而需要开始学习NASM。
第一个程序自然是不能免俗了。虽然这习俗似乎还是从高级语言传过来的。
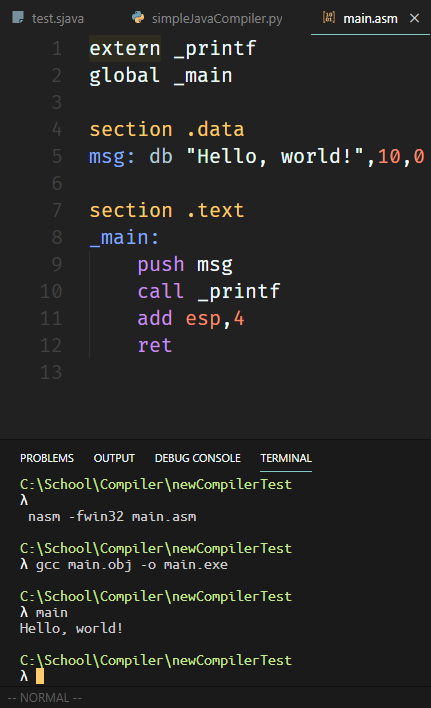
寄存器
刚上手的时候总归是真的非常凌乱。esp是啥? 为啥call了_printf之后要add esp, 4? push是啥? 为什么没有if else while这些关键字了?
先从寄存器开始吧。
对x86架构来说,有以下8个寄存器:
- EAX、EBX、ECX、EDX、ESP、EBP、ESI、EIP
其中最经常被用到的大概就是EAX和EBX了。由于历史原因,EAX用于累加,EBX用于存基地址,ECX是计数器,EDX用于存放除法的余数。
当初我学到这里的时候非常好奇为什么要叫这么蹩脚的名字,后来去查了一下。它们中的X表示pair。这是因为早期电脑一次能处理的比特数只有8或者16位。要想获取寄存器A的低8位,就写AL。相应的,高8位就是AH。合起来,要使用整个16位的寄存器,就是AX了。后来,从16位拓展到32位后,就在AX前面加个E,代表Extend。64位则是RAX,不过这个R我就没能查到意思了。
话说回来,EAX这4个寄存器,到了今天似乎已经没什么专用的必要了。只要在call function的时候注意遵守约定即可。而相对应的,ESP和EBP至今依然有着特殊用途。
栈
ESP是用来保存当前栈顶的地址的,而EBP是用来保存当前帧的帧底地址的。
那么帧和栈是什么?
在一个程序运行的过程中,系统会为它开辟一片内存地址,用于存储变量等。而程序又会把这块空间分割为主要两部分:
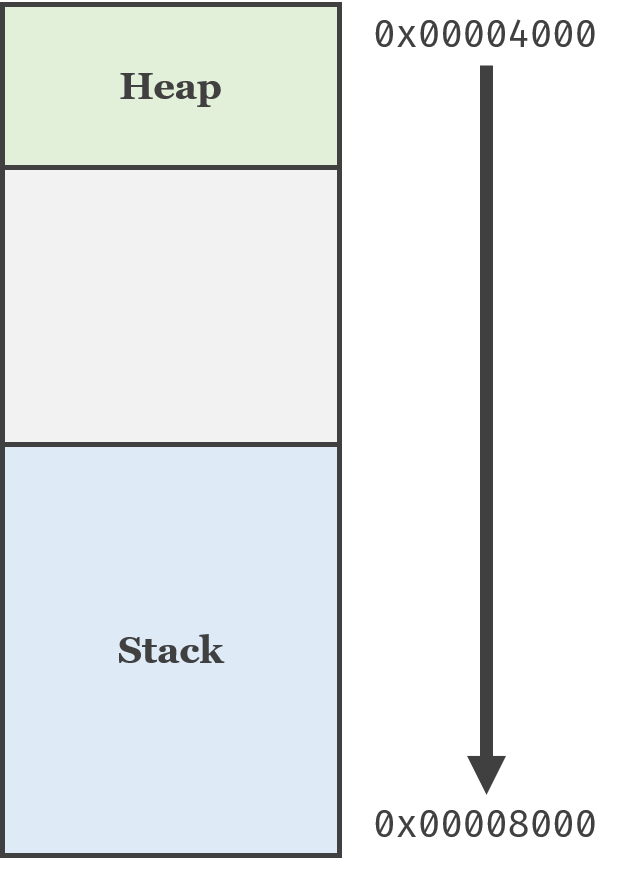
下面的stack就是栈了。
现在考虑如下代码:
int _add(int a, int b) {
return a + b;
}
int main() {
_add(3, 4);
return 0;
}
如果我们处在第二行,那么栈中会存在这样两个帧:
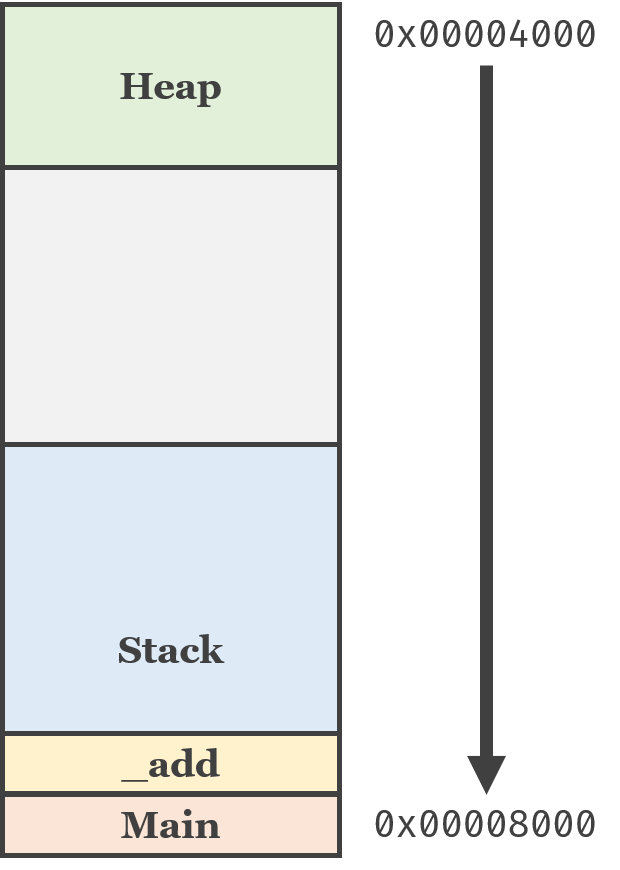
也就是说,一个函数运行时所临时占用的空间就算是帧了。
这样一来,也就很好理解递归爆深度的原因了:

理解了栈的模型后,就很好理解push和esp了。
比方说,执行以下x86汇编代码:
push 893
机器就会把893放进栈里:
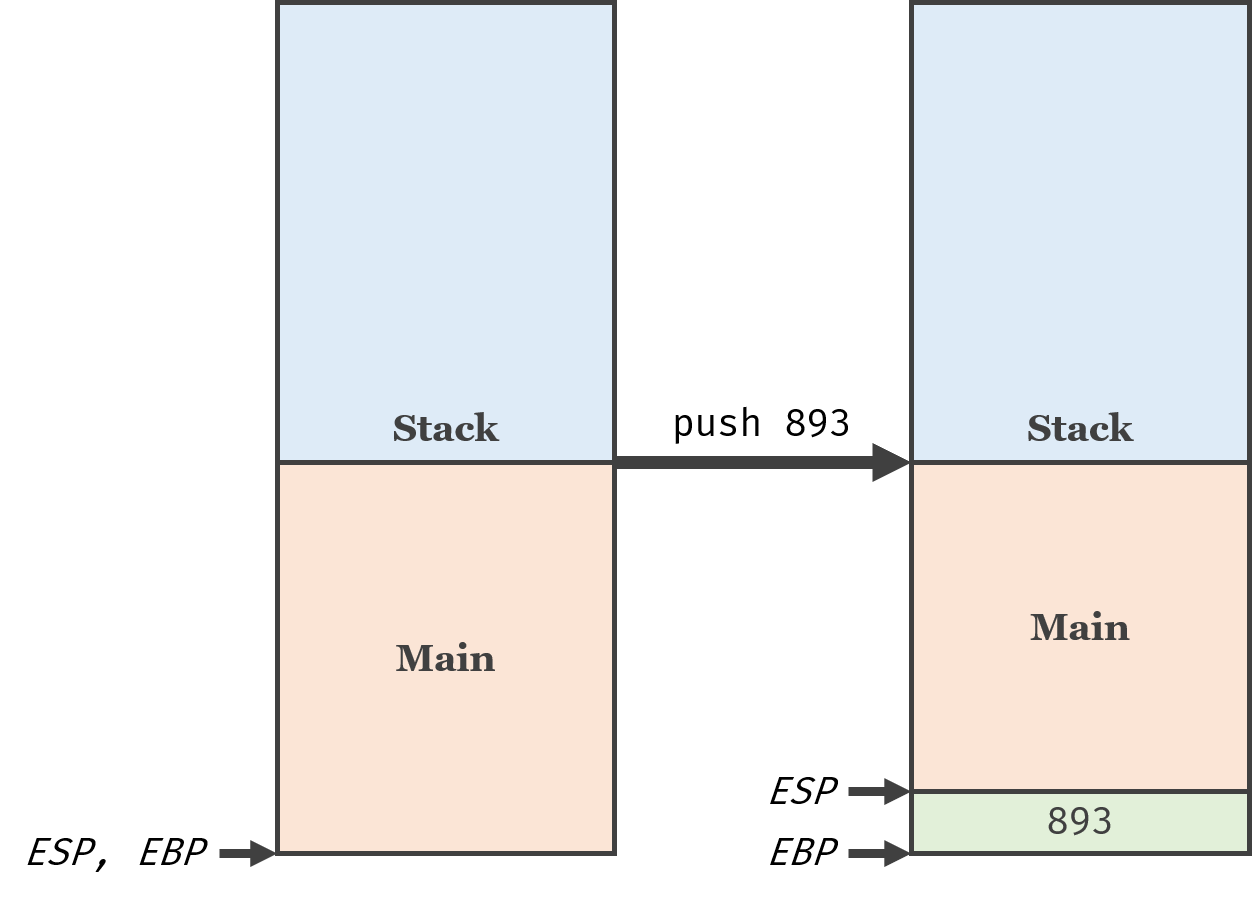
鉴于893需要4个字节,所以ESP会减少4,而EBP不变。
所以,上面的hello world中,add esp, 4实际上等同于把栈中的指针给pop掉了。
基本指令
光会push是不够的。
| Assembly | C |
|---|---|
mov a, b | a = b |
add a, b | a += b |
push a | |
pop a | |
call a | a() |
inc a | ++a |
我想,知道了add,应该很容易能推出sub,mul等方法,所以这里省去了相当多的指令。
函数调用
汇编里,call a就是调用函数a了。那么要怎么传递参数呢? 返回值又要怎么办呢?
这里就又要请esp和栈出场了。为
在调用函数前,逆序把数据push进栈中:
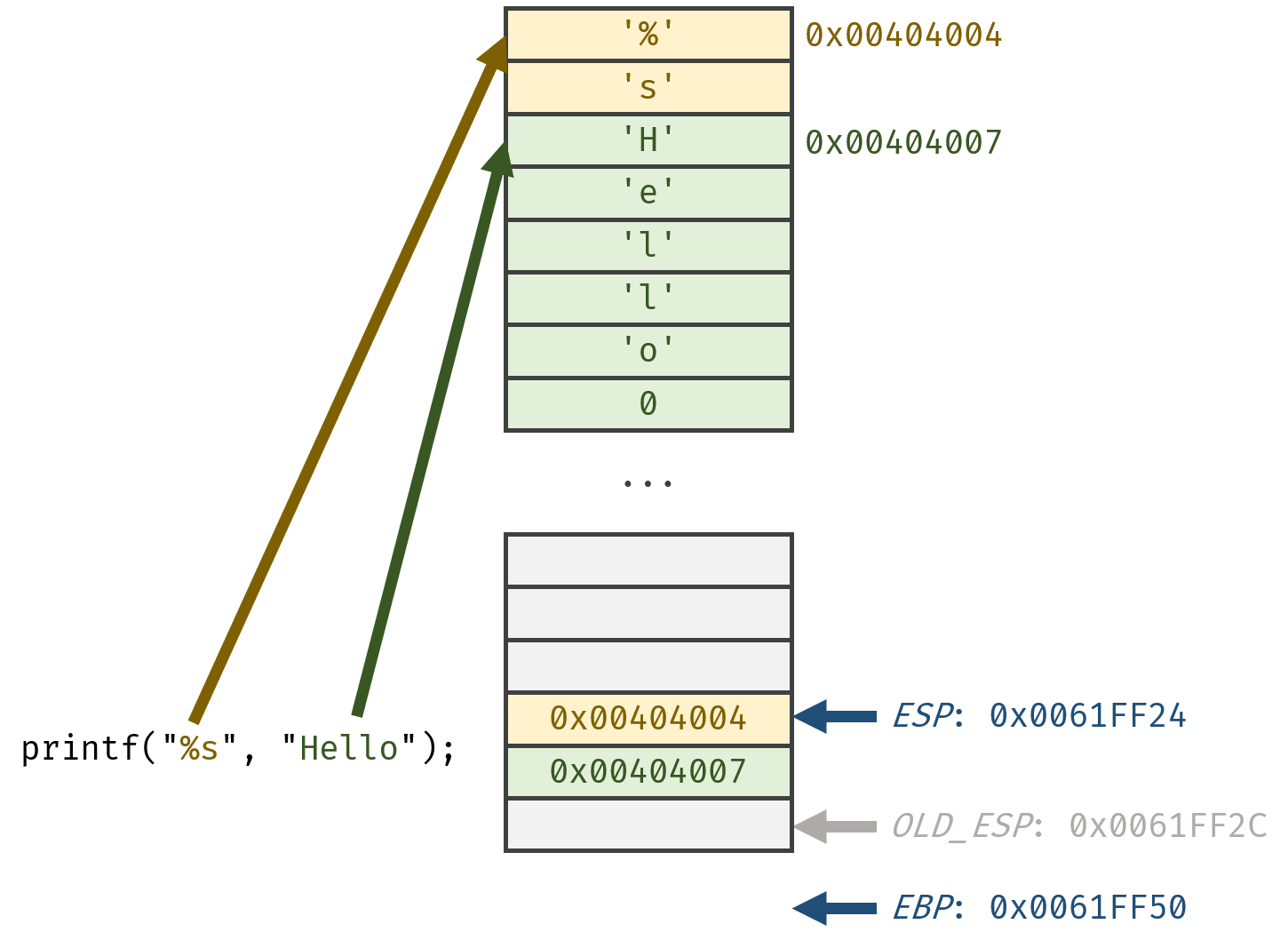
之后call _printf即可。
以上数据均为真实数据。所用代码如下:
extern _printf
global _main
section .data
_a: db "%s", 0
_b: db "Hello", 0
_fmt: db "%d %d", 0Ah, 0
section .text
_main:
push _b
push _a
push _fmt
call _printf
add esp, 12
push esp
push ebp
push _fmt
call _printf
add esp, 12
mov eax, 0
ret
输出结果如下:
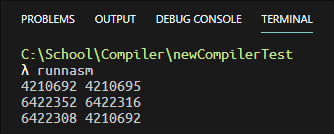
那么如果是自定义函数的话,要怎么利用栈中的参数呢?
很简单,利用esp + offset即可取值:
extern _printf
global _main
section .data
_fmt: db "%d", 0Ah, 0
_a: dd 4
_b: dd 5
section .text
_add:
mov eax, dword [esp + 4]
mov ebx, dword [esp + 8]
add eax, ebx
ret
_main:
push 4
push 5
call _add
add esp, 8
push eax
push _fmt
call _printf
add esp, 8
ret
神奇的是,windows上只需要偏移量+4即可,而网上的教程无一不是偏移量+8。而我也始终想不明白为什么windows只需要偏移量+4,难道不用存储PC的值和之前的EBP吗?
接下来是返回值。根据函数调用约定,似乎函数的返回值都是存在EAX内的。
因此,在调用函数前,最好先push eax,等esp清理完参数后,再恢复eax的值,避免意外被覆盖。
AST
在开始写AST转ILOC的代码之前,先得实现AST。
AST本身和ParseTree非常像。唯一不同的是,ParseTree是根据每个节点的产生式序号映射属性文法动作的。而AST是根据预先定义的actionID来查找对应动作并执行的。
因此,很容易写出其源码。
ILOC
全称是Intermediate Language for Optimizing Compiler。然而我在开始写这个编译器的时候就知道,能写出来,并且写的正确,就足够了。我真的不奢求能做到什么优化。因此,尽管用了ILOC这个名字,却根本没有拿它做任何优化,也是多少有些奇葩了。
我认为,转换成高层次IR后再转换成NASM,尽管提供了添加代码优化的可能性,但所需要的代码量会更多,而我还希望给自己的寒假留下一些用在其他兴趣爱好上的时间。所以我决定直接从AST生成几乎就是直接可编译的NASM代码。
终于该开始写代码了!首先,为了能够看到输出,得先把functionCall给写好:
@aar.action("functionCall")
def _funcCall(funcCall, funcName, paramList):
if str(funcName) in builtinFunctions:
builtinFunctions[str(funcName)](paramList)
就是说,如果是内建函数,就直接调用内建函数来生成NASM代码。
simpleJava的打印叫print,因此先来实现它:
builtinFunctions = {}
def builtin(functionName):
def decorate(function):
builtinFunctions[functionName] = function
return function
return decorate
@builtin("print")
def _print(paramList):
addEXTERN("_printf")
fmtParam = []
totSize = 0
for param in paramList.getChilds()[::-1]:
paramList.cb.addILOC("push", param.var.getOP())
totSize += param.var.size
type_ = param.var.type
if type_ == "int":
fmtParam.append("%" + "d")
elif type_ == "String":
fmtParam.append("%" + "s")
fmtParam.reverse()
fmtVarName = getTempVarName()
addDATA(fmtVarName, "db", '"' + " ".join(fmtParam) + '"' + ", 0Ah, 0")
paramList.cb.addILOC("push", fmtVarName)
paramList.cb.addILOC("call", "_printf")
paramList.cb.addILOC("add", "esp", str(totSize + 4))
总的来说,就是根据调用的参数的类型,生成格式化字符串,并且生成调用以及清理栈空间的代码。
最终的打印工作还是交给了printf来做,果然怎样都绕不开C语言啊(笑)
这里采用的是xxx.cb.addILOC()的方法来添加ILOC,其中的cb是当前节点所属的代码块。代码块是在实现了if else while for等结构化流程控制语句之后的产物,所以会之后讲。
写完之后运行的效果如下:
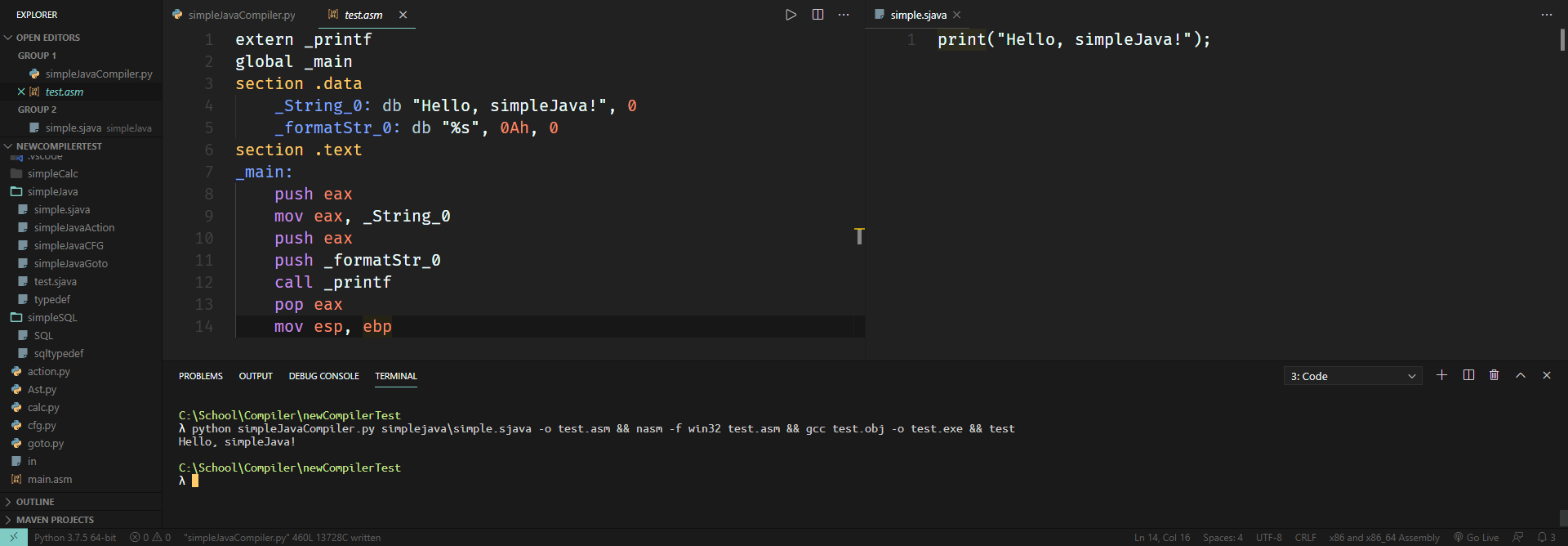
只能打印数字和字符串是远远不够的。起码得能打印变量吧? 因此,先把变量声明给写了:
@aar.action("varDec", index=0)
def _varDec(varDec, type_, idList):
for node in idList.getChilds():
node.dec = True
node.type = type_.getContent()
node.isArray = type_.isArray
node.dim = type_.dim
@aar.action("id_var")
def _id_var(id_):
varName = "__v_%d_%d_%s" % (id_.ns[0], id_.ns[1], id_.getContent())
if "dec" in id_:
if id_.type[0].islower():
id_.var = Variable(varName, id_.type, id_.ns)
else:
ns = id_.ns
while True:
tempVarName = "__v_%d_%d_%s" % (ns[0], ns[1], id_.getContent())
if tempVarName in declaredVars[ns]:
id_.var = declaredVars[ns][tempVarName]
break
if ns not in nsInheritance:
print("[ERROR] Undefined variable: %s has not been declared yet." % varName)
exit()
ns = nsInheritance[ns]
通过Variable类,可以统一地管理变量对象所具有的name, size, type, namespace等属性。namespace也是引入if else while之后的内容,之后再说明。
之后,把变量的运算给写好:
@aar.action("assign")
def _assign(assg, l, r): pass
@aar.action("add")
def _add(add, l, r): pass
...
@aar.action("sub")
def _sub(sub, l, r): pass
@aar.action("imod")
def _imod(imod, l, r): pass
以上是算术运算。接下来,需要实现条件运算,也就是a == b,not (a or b)之类的。
我决定把条件运算的返回值设定为int。不过这样就引出了一个问题: NASM中,用于比较的cmp的结果只会存放在CPU的flags寄存器中。
上网查了一下,有个叫LAHF的神奇指令,可以把CPU flags寄存器的值搬到AH,也就是EAX的第8 ~ 15比特。
鉴于cmp a, b实际上是a - b,然后把结果存入寄存器中。因此,若a == b,则相减结果为0,导致Zero Flag被设为1。由于Zero Flag是AH的第7位,因此不难得出应该左移8 + (7 - 1) = 14位,再与1做与操作,就能得到int类型的结果了。ne类似,只需要多加一步xor eax, 1反转答案即可。
a < b是利用Sign Flag,即正负号的标记。若是1则说明是负数。因此,cmp a, b后,若SF是1,则说明a - b < 0,即a < b。鉴于SF是AH最高的第8位,因此需要左移15位再与1做与操作才能得到int类型的结果。
a >= b则正好处在a < b的反面。因此,只需要复制a < b的代码,多加一步xor eax, 1即可。
>和<=同理。
于是就很好实现了。
这样生成的代码会非常的臃肿,经常会有pop ebx下一句就是push ebx的情况。但是----哎,既然前面做了想要尽快完成代码的决定,那... 大概也就可以心安理得地划水不好好考虑优化了吧。
代码块
接下来该开始写流程控制语句了。先来把代码块类写好:
class CodeBlock:
def __init__(self, name):
self.name = name
self.list = []
self.next = None
self.segment = []
def addILOC(self, op, *l):
self.list.append((op, *l))
显而易见的是,每个statementList都会对应着一块全新的代码块,因此写个简单地动作注册器,生成cb:
firstAAR = ASTActionRegister()
@firstAAR.action("stmtList", index=0)
def _stmtl(stmtl, *rest):
stmtl.cb = CodeBlock(getNewCodeBlockName())
ast.evaluate(firstAAR)
再把位于stmtl节点上的所有cb下推到所有节点,注意不要覆盖子节点的cb:
def updateCB(cur, childs):
for child in childs:
if "cb" not in child:
child.cb = cur.cb
child.run(updateCB)
ast.run(updateCB)
流程控制语句
终于开始写流程控制语句了。就像是刚学编程那会一样,慢慢掌握复杂的语法。只不过这一次,要把掌握换成实现。
大家都知道,if之类的语句,就是判断如果正确就跳到内部的代码块去执行,完事再跳回来。
的确如此。跳到内部代码块不难,只需要cmp + jz的组合即可。但是,要怎么跳回来呢?
显然,只能在每个if对应的代码块里,追加上jmp ...,跳到if后面的代码块。这样一来,就势必要把if后面的语句块拆开来,当作新的代码块来处理了:

while也是同理:

上图分别把print("half life 3!!!")和print("wow")划分成了新的代码块。
看起来很简单。但是,在用AST生成ILOC的时候,却不能直接确定下一个代码块是哪个。以上面的while作为例子:
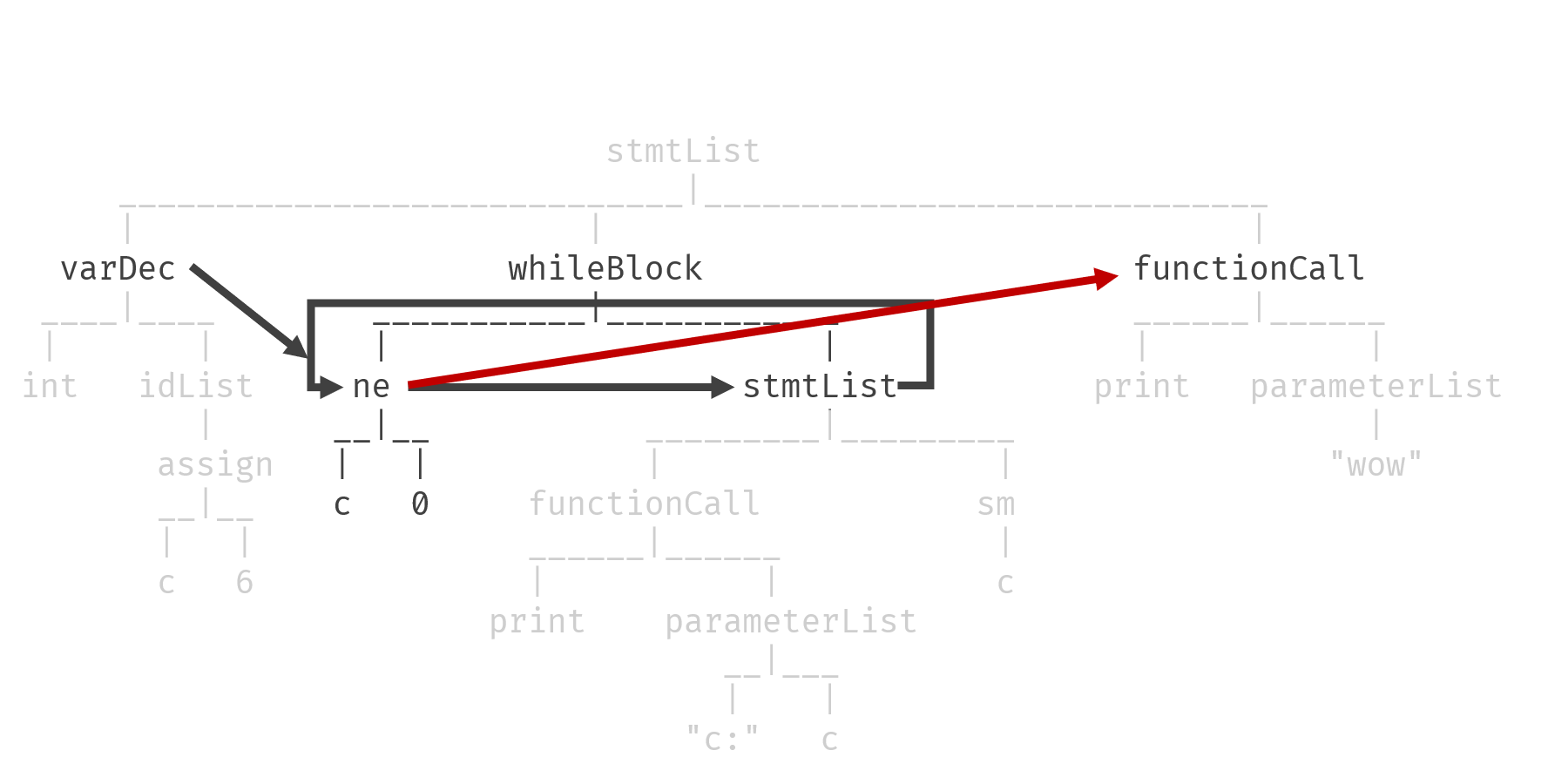
为了说明方便起见,假定临时变量__t = (c != 0)。在求完__t的值之后,就应该根据它的值,确定是继续往下执行stmtList中的语句,还是直接跳到后面的functionCall。
先写上判断:
mov eax, dword [__t]
cmp eax, 0
jz ...
上面的代码先从内存中取出__t的值,放到寄存器eax中。之后,通过cmp,执行eax - 0,并将结果存放在CPU的flag中。之后,jz是指,如果zero flag是1,也就是说eax - 0 == 0,则jmp到...
jmp到哪呢? 这需要获取父节点的兄弟节点的数据...实在是不怎么现实。而且,此时这个兄弟节点还没被划分成新的代码块。即便将父节点的兄弟节点的代码块修改成了新生成的代码块,那还需要把这个兄弟节点之后的每个节点的代码块都改成新的。若是出现了很多个平行的while块,用脚想都知道是$\mathcal{O}(n^2)$的复杂度。再怎么不考虑编译器的速度也不能采用这么脏的实现啊。
是不是可以通过一遍后序遍历把每个节点代码块后面会跟着的代码块提前算出来呢? 很遗憾,也许是因为太久没有做过树形dp,我想了很久都没有发现对任意节点都通用的情况。
所以,我想最好的办法还是先不写判断,用伪指令if cond, val, codeblock来表示如果cond == val则跳转到codeblock,否则继续向下执行。
这样做的好处大概是,if可以被重复使用。也就是说,if语法块可以利用if指令描述,while语法块也可以利用if语法块描述,for同理。
在if块结束之后,添加一条指令,跳转到if语法块后面的部分。由于这个后面的部分要等到整颗AST都遍历完后才能确定,所以现在就只用一个元组代表需要之后再计算即可。
实现在此。
@aar.action("ifBlock")
def _ifBlock(ifb, *childs):
for i in range(1, len(childs), 2):
c0, sl = childs[i - 1], childs[i]
ifb.cb.addILOC("if", c0.var, "1", sl.cb, ("cur", "next"))
# ...
@aar.action("whileBlock")
def _while(while_, c0, sl):
sl.cb.next = (while_.cb, "next")
while_.cb.addILOC("goto", sl.cb)
sl.cb.addILOC("goto", sl.cb)
# ...
那么这个(cb, "next")和("cur", "next")要怎么计算呢?
首先,根据goto指令,分割语法块。这是显而易见的: goto到其他程序段后,后面的代码自然不可能执行,除非从别的语法块跳回来。因此,可以写出如下代码:
class CodeBlock:
def calcSegment(self):
self.segment.clear()
segCount = 0
for op, *_ in self.list:
self.segment.append(segCount)
if op == "goto":
segCount += 1
def getSegments(self):
self.calcSegment()
newCBs = [self] + [CodeBlock(self.name + "_SEG_%d" % i) for i in range(1, self.segment[-1] + 1)]
for i in range(len(self.list)):
if self.segment[i]:
newCBs[self.segment[i]].addILOC(*self.list[i])
i = len(self.list) - 1
while self.segment[i]:
self.list.pop()
i -= 1
for i in range(len(newCBs) - 1):
l, r = newCBs[i], newCBs[i + 1]
l.next = r
return newCBs
cbs = {EXIT_BLOCK}
def getCB(cur, *childs):
cbs.add(cur.cb)
ast.apply(getCB)
# split code blocks by goto
que = deque(cbs)
while que:
cb = que.pop()
segmentation = cb.getSegments()
for i in range(1, len(segmentation)):
cbs.add(segmentation[i])
que.append(segmentation[i])
在分割的过程中,可以计算出被分割各块的next:
for i in range(len(newCBs) - 1):
l, r = newCBs[i], newCBs[i + 1]
l.next = r
分割完后,不可能再更改每条语句所属的代码块,因此可以在此时把"cur"替换成代码块对象的引用:
def updateCur(self):
for i, (_, *rest) in enumerate(self.list):
self.list[i] = list(self.list[i])
for j in range(len(rest)):
if isinstance(rest[j], tuple):
if isinstance(rest[j][0], str) and rest[j][0] == "cur":
self.list[i][j + 1] = (self, rest[j][1])
之后,扫描所有产生的代码。根据if和goto伪指令内要跳转到的元组,建立代码块之间的依赖图。还请注意,如果A需要B的next,那么就从(B, "next")连一条边到A。这样反直觉的连法是为了之后利用拓扑排序,将所有(cb, "next")这样未定的元组替换为确定的CodeBlock对象。
# If A would like to goto B.next, we have to calculate
# B.next first before calculate A.
# If A.next is (B, next), then we have to calculate
# B.next before calculate CB that containing A.next.
nextDependency = {}
indeg = {k: 0 for k in cbs}
for cb in cbs:
if isinstance(cb.next, tuple):
nextDependency.setdefault(cb.next, []).append((cb, "next"))
indeg[cb.next] = 0
indeg[(cb, "next")] = 0
for op, *_ in cb:
if op == "goto":
dest = _[0]
if isinstance(dest, tuple):
nextDependency.setdefault(dest, []).append(cb)
indeg[dest] = 0
indeg[cb] = 0
elif op == "if":
lop, rop, dest = _
if isinstance(dest, tuple):
nextDependency.setdefault(dest, []).append(cb)
indeg[dest] = 0
indeg[cb] = 0
然后应用拓扑排序:
for k, v in nextDependency.items():
for dest in v:
indeg[dest] += 1
# toposort
que = deque(k for k in indeg if not indeg[k])
while que:
cur = que.pop()
if isinstance(cur, tuple):
cur[0].updateNext()
else:
cur.updateNext()
if cur in nextDependency:
for v in nextDependency[cur]:
if v not in indeg:
que.append(v)
indeg[v] -= 1
if not indeg[v]:
que.append(v)
其中,updateNext()方法会扫描当前cb中所有语句中的所有参数,并将所有未定的代码块对象替换成已经计算好的代码块对象。显然,当cur被弹出双出队列时,说明它已经没有入边,也就是说它的所有依赖已经被计算好了,因此可以放心的调用updateNext方法。该方法实现如下:
class CodeBlock:
def updateNext(self):
# update operands containing next of other CB
if isinstance(self.next, tuple):
self.next = self.next[0].next
for i, (_, *rest) in enumerate(self.list):
self.list[i] = list(self.list[i])
for j in range(len(rest)):
if isinstance(rest[j], tuple):
self.list[i][j + 1] = self.list[i][j + 1][0].next
最后,把goto和if伪指令替换成真正可执行的NASM语句:
# change if and goto to jz and jmp
for cb in cbs:
for i, (op, *rest) in enumerate(cb):
cb.list[i] = list(cb.list[i])
if op == "goto":
cb.list[i][0] = "jmp"
if cb.list[i][1] is None:
cb.list[i][1] = EXIT_BLOCK
ControlFlowGraph.setdefault(cb, []).append(cb.list[i][1])
elif op == "if":
c0, const, st = rest
if st is None:
st = EXIT_BLOCK
cb.list[i] = [
["push", "ebx"],
["mov", "ebx", c0.getOP()],
["cmp", "ebx", const],
["pop", "ebx"],
["jz", st]
]
ControlFlowGraph.setdefault(cb, []).append(st)
这里,ControlFlowGraph是用来确定哪些代码块是不会跳转到其他任何代码块的。这些代码块需要在末尾添加跳转到_exit代码段的指令,否则就会跨过代码段的间隔,继续向下执行。
简单地求一下ControlFlowGraph各顶点的出边数,出边为0就添加jmp _exit即可。
# check cb that need jmp to _exit
outdeg = {}
for src, dests in ControlFlowGraph.items():
outdeg[src] = len(dests)
for dest in dests:
if dest not in outdeg:
outdeg[dest] = 0
for k, v in outdeg.items():
if not v:
k.addILOC("jmp", EXIT_BLOCK)
最后打印语句,即可获得输出:
for ex in EXTERN:
print("extern %s" % ex)
print("global _main")
print("\nsection .data")
print("\n".join(DATA))
print("\nsection .bss")
print("\n".join(BSS))
print("\nsection .text")
for cb in cbs:
print("%s:" % cb.name)
for line in cb:
if not isinstance(line[0], list):
print(" %s %s" % (str(line[0]), ", ".join(str(_) for _ in line[1:])))
else:
for l in line:
print(" %s %s" % (str(l[0]), ", ".join(str(_) for _ in l[1:])))
以这段代码作为输入例:

会产生这样的输出:

Continue & Break
考虑如下输入:
int c = 10;
print("Rocket Launch Countdown...");
while (c != 0) {
--c;
if (c == 7) {
print("seven");
continue;
} else if (c == 3) {
for (int i = 0; i < 3; ++i) {
print("Count Down Interrupted!!");
}
break;
}
print(c);
}
print("BOOOOM!!!");
可以看得出来,不论是continue,还是break,都需要跳转到它们所属的statementBlock之外:

因此,需要设定两个全新的属性: loopBlock和breakBlock,分别说明如果接下来出现了continue和break,则分别应该往哪个block的起点或哪个block的nextBlock跳转:
def updateBreakBlock(cur, childs):
for child in childs:
child.bb = cur.bb
child.run(updateBreakBlock)
def updateContinueBlock(cur, childs):
for child in childs:
child.lb = cur.lb
child.run(updateContinueBlock)
@aar.action("whileBlock", index=1)
def _while_1(while_, c0, sl):
sl.lb = sl.cb
sl.run(updateContinueBlock)
sl.bb = while_.cb
sl.run(updateBreakBlock)
sl.cb.addILOC("if", c0.var, "0", (while_.cb, "next"))
这样,sl.lb = sl.cb,那么不论处在多深的嵌套中,只要没有被其他更深层的while覆盖,那么continue依然可以正常的跳转到sl的起点,而sl.bb = while_.cb则可以让break跳转到while_.cb的下一个代码块:
@aar.action("break")
def _break(break_):
break_.cb.addILOC("goto", (break_.bb, "next"))
@aar.action("continue")
def _continue(continue_):
continue_.cb.addILOC("goto", continue_.lb)
由于之前已经写好了对goto和if伪指令的操作,因此除了添加上面几个简单的函数之外,无需任何改变就可以实现continue和break了,可喜可贺。
编译上面的迫真火箭发射程序并运行可以获得如下结果:
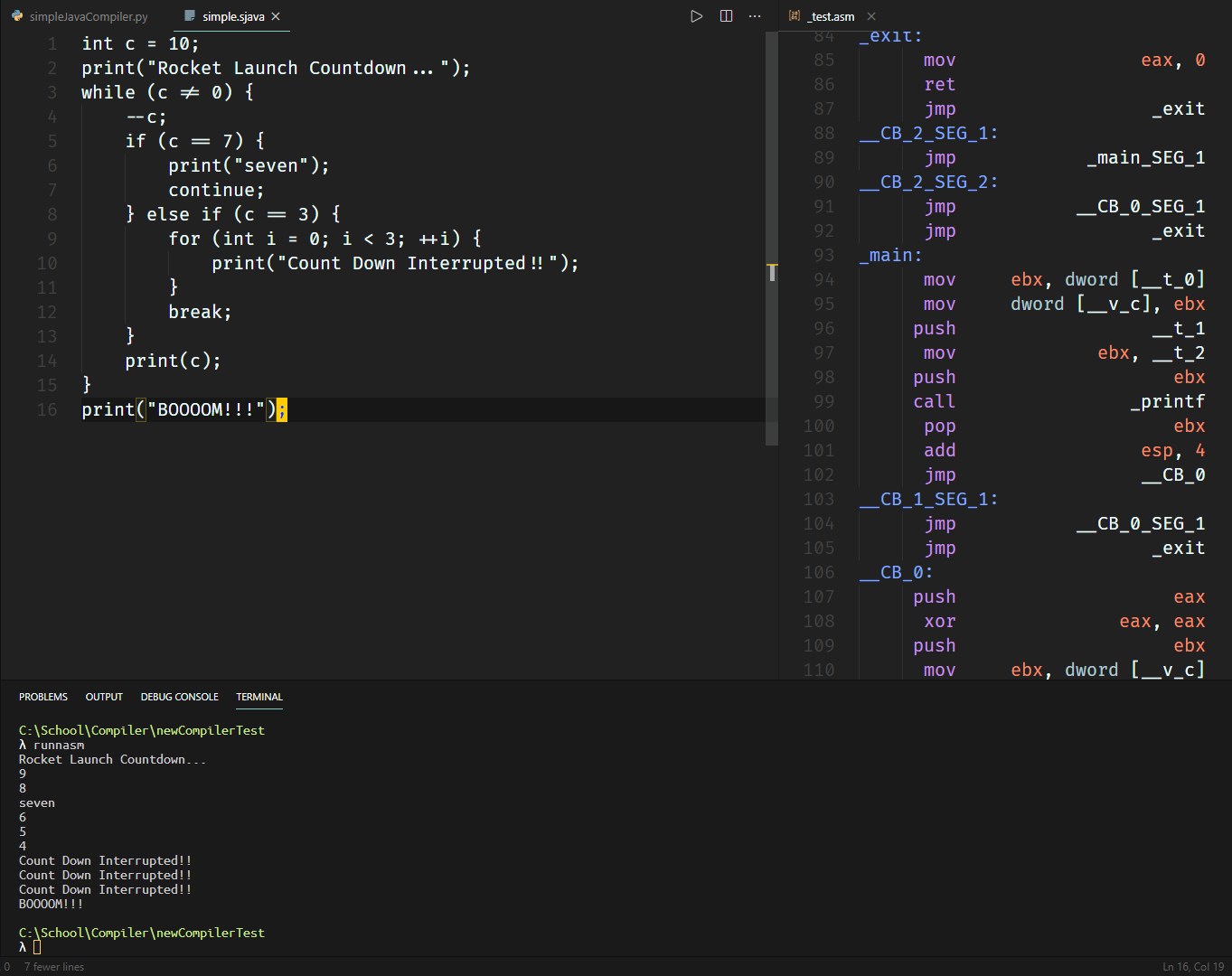
函数声明
之前已经说明过了函数该如何调用。因此,接下来就只需要实现函数的声明,以及根据函数声明产生调用代码就可以了。
首先,就像是Variable类一样,设定一个Function类,用来记录返回值,标识符,参数列表和语句列表。
declaredFunctions = {}
class Function:
def __init__(self, returnType, name, parameters, sl):
self.returnType = returnType
self.name = name
self.parameters = parameters
self.sl = sl
def __str__(self):
return "%s(%s)" % (self.name, ", ".join("%s %s" % (var.type, var.name) for var in self.parameters))
def __repr__(self):
return repr(str(self))
之后,只需要在funcDec节点执行创建函数的操作即可:
@aar.action("defParam")
def _defParam(defp, type_, id_):
varName = "__v_%d_%d_%s" % (id_.ns[0], id_.ns[1], id_.getContent())
if type_.getContent()[0].islower():
defp.var = Variable(varName, type_.getContent(), defp.ns)
@aar.action("defParamList")
def _defParamList(defpl, *defps):
defpl.list = [_.var for _ in defps]
@aar.action("funcDec", index=0)
def _funcDec_0(func, type_, func_id, defpl, sl):
defpl.ns = sl.ns
defpl.run(updateNS)
@aar.action("funcDec")
def _funcDec(func, type_, func_id, defpl, sl):
funcName = str(func_id.getContent())
declaredFunctions[funcName] = \
Function(
str(type_.getContent()),
funcName,
defpl.list,
sl.cb
)
不过,到了这里,就开始涉及到严重的问题了:
变量的作用域还没有设定。
因此,需要引入作用域。由于对作用域和命名空间的认知有些混乱,之后可能会交叉使用这两个名字。
一个非常简单的想法就是,作用域由两个数字来描述,分别是:
- 嵌套深度
- 在该深度下是第几个代码块
考虑到每个statementList都会产生新的代码块,所以只需要利用一个简单的函数就可以实现:
depth = -1
count = {} # depth: count
def initNS(cur, childs):
global depth
if cur.getContent() == "stmtList":
depth += 1
if depth not in count:
count[depth] = -1
count[depth] += 1
cur.ns = (depth, count[depth])
for child in childs:
child.run(initNS)
depth -= 1
else:
cur.ns = (depth, count[depth])
for child in childs:
child.run(initNS)
declaredVars[cur.ns] = {}
ast.run(initNS)
把命名空间打印出来大致如下:
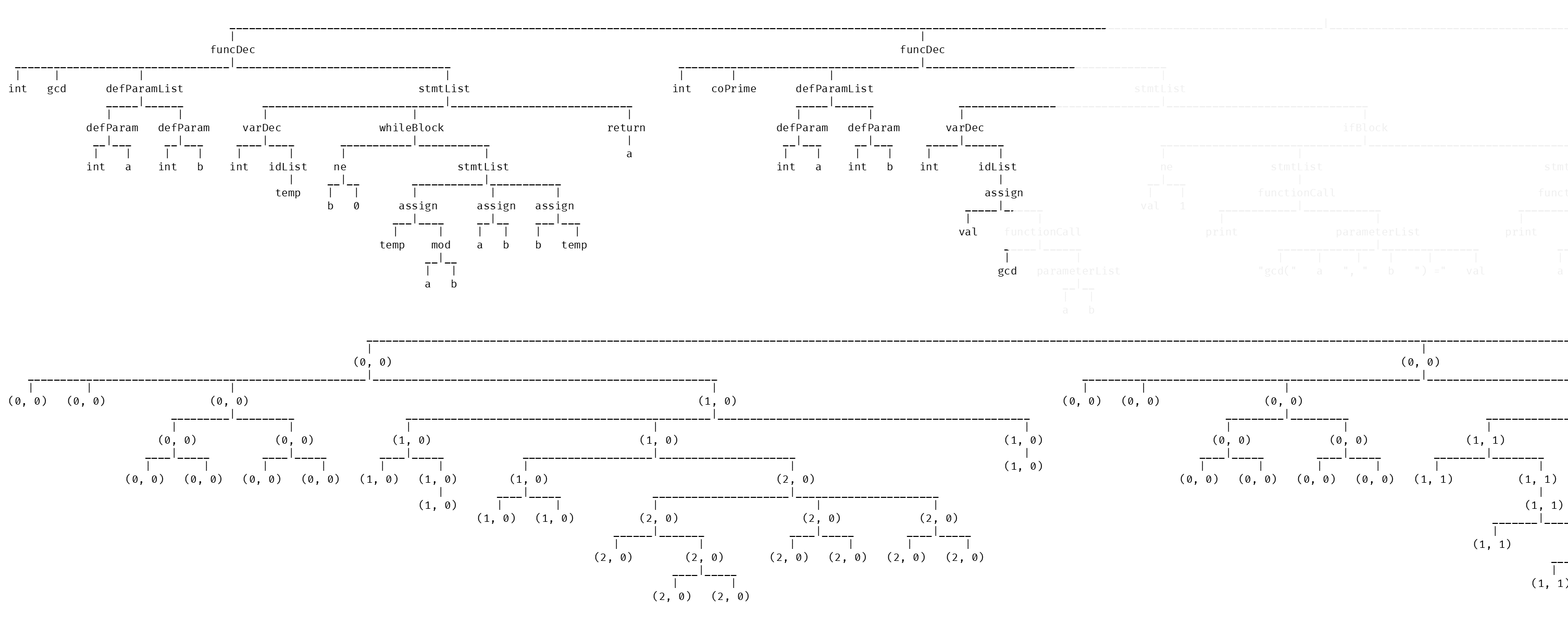
上半部分和下半部分的节点是一一对应的,很容易就能看出来每个节点对应的命名空间。
有了命名空间之后,就应该考虑一下查找的问题了。
很显然,从当前节点一路向上溯根,在每个经过的节点上看一下当前正在查询的id是否在当前节点对应的命名空间内被声明过即可。
但是由于没有提供father的引用,因此要使用额外的数据。在这里,我用了一个字典nsInheritance,记录子命名空间到父命名空间的映射关系:

由于是树状结构,因此每个子命名空间必定只能对应一个父命名空间,所以简单映射一下即可。
之后的查找,实现起来也很简单:
@aar.action("id_var")
def _id_var(id_):
varName = "__v_%d_%d_%s" % (id_.ns[0], id_.ns[1], id_.getContent())
if "dec" in id_:
if id_.type[0].islower():
id_.var = Variable(varName, id_.type, id_.ns)
else:
ns = id_.ns
while True:
tempVarName = "__v_%d_%d_%s" % (ns[0], ns[1], id_.getContent())
if tempVarName in declaredVars[ns]:
id_.var = declaredVars[ns][tempVarName]
break
if ns not in nsInheritance:
print("[ERROR] Undefined variable: %s has not been declared yet." % varName)
exit()
ns = nsInheritance[ns]
这样的话,就算重名了也没关系了。
接下来,要在函数的statementList被解析并生成ILOC前,需要给它的代码块加上从栈中读取参数的代码:
@aar.action("funcDec", index=3)
def _funcDec_3(func, type_, func_id, defpl, sl):
offset = 4 # return address need 4 bytes
for var in defpl.list:
sl.cb.addILOC("mov", "ebx", "[esp + %d]" % offset)
sl.cb.addILOC("mov", var.getOP(), "ebx")
offset += var.size
最后,补全生成函数调用的代码:
@aar.action("functionCall")
def _funcCall(funcCall, funcName, paramList):
if str(funcName) in builtinFunctions:
builtinFunctions[str(funcName)](paramList)
else:
func = declaredFunctions[str(funcName)]
if len(paramList.getChilds()) != len(func.parameters):
print("[ERROR] Function call: Parameter number don't match.")
exit()
funcCall.cb.addILOC("push", "eax")
funcCall.cb.addILOC("push", "ebx")
totSize = 0
for i in range(len(func.parameters) - 1, -1, -1):
if not match(func.parameters[i], paramList.list[i]):
print("[ERROR] Function call: Parameter %d don't match." % i)
exit()
var = paramList.list[i]
funcCall.cb.addILOC("push", var.getOP())
totSize += var.size
funcCall.cb.addILOC("call", func.sl.name)
funcCall.cb.addILOC("add", "esp", str(totSize))
funcCall.var = Variable(getTempVarName(), func.returnType, funcCall.ns)
funcCall.cb.addILOC("mov", funcCall.var.getOP(), "eax")
funcCall.cb.addILOC("pop", "ebx")
funcCall.cb.addILOC("pop", "eax")
这样就可以实现函数调用了。
成果
根据这些已经实现的代码,写一点可以跑的简短程序,作为最后的综合测试:
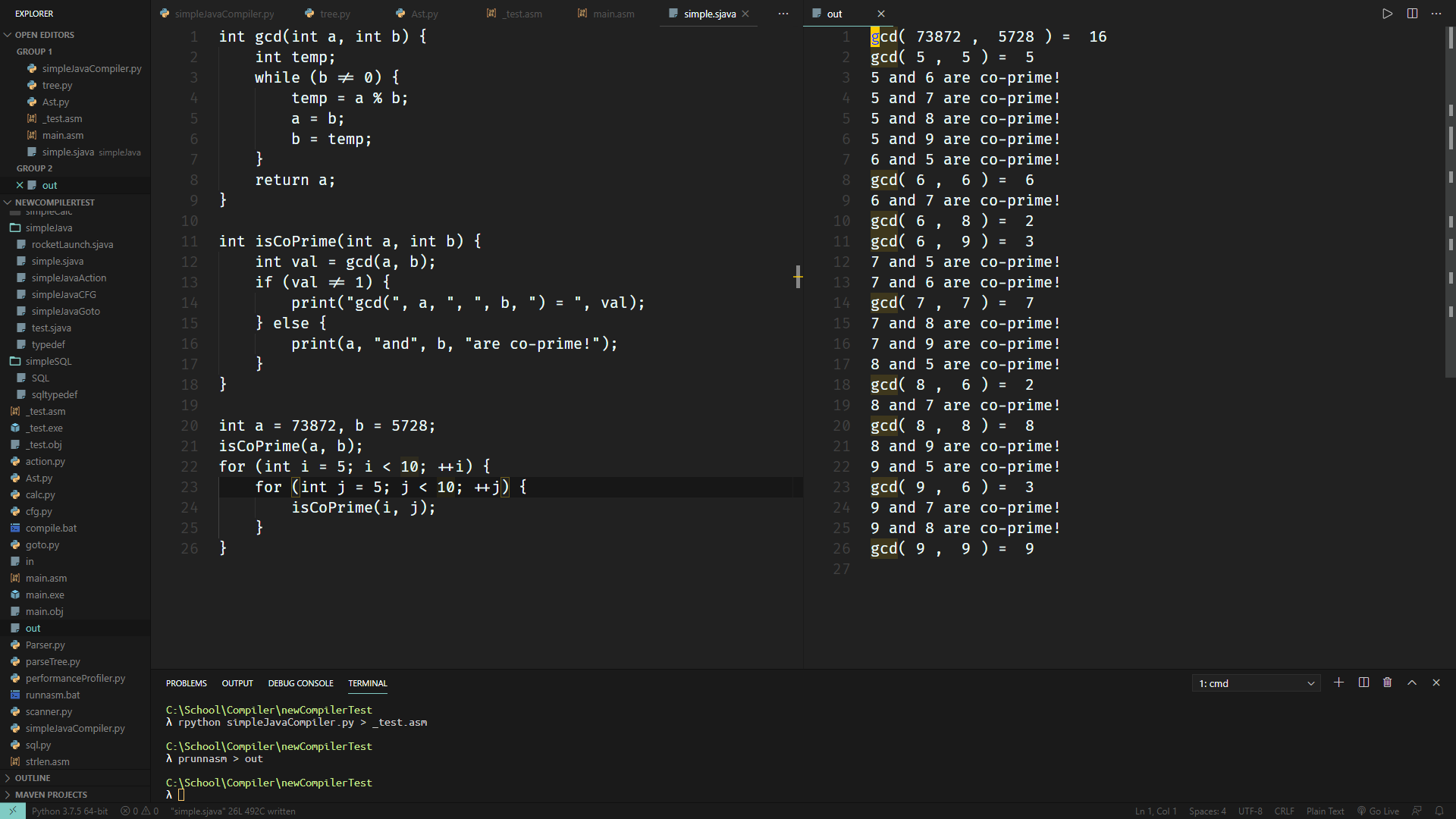
它生成的代码如下:

完结撒花。
反思
学到了很多,也思考了很多。
尽管了解了寄存器,了解了运行原理,了解了汇编的写法。但我总觉得,还远远不够啊。
连数组都没有实现; 只是因为觉得要实现引用的话还得先实现类定义就嫌麻烦; 不知道汇编要怎么分配堆内存于是就想着跳过。好像不论做什么项目,回过头一看,理想总是丰满,现实何止骨感。
除了因为各种原因而没有实现的内容之外,在写这个编译器的时候,我总是在不停地想。
究竟怎样才能够写出灵活的架构呢?
虽然按照词法分析->句法分析->文法分析->IR->Code这样走下来,确实前面的部分不会太多干涉到后面的部分。比方说,就算要把CFG换成全新的文法,也只需要改一下直接相关的ParseTree的动作,后面已经写好的IR根本不用动。
但是,每个部分的内部,总是会显得不那么灵活。引入代码块的时候,我把前面几乎所有的action都重写了一遍,因为要加上.cb。引入命名空间时,居然会因为查找算法的bug而导致不能够正常运转,之前已经能编译的程序居然也会开始报错。又或者,为了提高性能,最后居然要重写整个模块。
是因为写到后面就开始心急了吗? 是因为后面,已经开始进入教科书不会详细说明的部分了吗?
如果我现在突然希望加入优化器呢? 那优化器的结构又该是怎样呢? 现在的结构能够以很小的代价支持优化器的加入吗? 现在的IR真的算得上是合格的IR吗? 能跑就是全部吗? 为什么不先去看看工业级的编译器的架构呢? 难道自己就只满足于小打小闹般的写着玩吗? 以这么低的水准要求自己合适吗?
这样的问题,我只能在心里默默地问,却不知道怎么回答。
不敢面对。
好像每次只要自己开始写一些巨大的东西,就会犯各种错误。总是会写着写着发现当初没有考虑到这样那样的需求,而功能的分离又总是做的很差,于是每写一段时间就要花更多的时间拿来优化项目的结构。这样循环往复迭代几次,也就到了我能够承担的项目的极限大小了吧。如果说老师的能力是随手处理几十万行的C++程序的话,那么才几千行python的我,修行之路真的还很漫长啊。
好像每次只要在开始写之前没有非常详尽的对类的安排以及实现方案的话,就非常容易写着写着开始面向实现编程,再次回到ACM的路上,只要能写出来能跑就行,不考虑任何未来的需求。
我想,接下来到开学前那段时间,可能需要好好花时间修行设计模式才行了。
也许再过一段时间,回头一看。
又会像去年12月那样,像批评minecrash那样批评这个编译器了吧。
未尝不是一件好事呢。
References
- http://leto.net/writing/nasm.php
- https://stackoverflow.com/questions/37407363/create-an-exe-file-in-assembly-with-nasm-on-32-bit-windows
- https://kakaroto.homelinux.net/2017/11/introduction-to-reverse-engineering-and-assembly/
- https://blog.csdn.net/gyrfalcon_sky/article/details/21713481
- https://pdos.csail.mit.edu/6.828/2008/readings/i386/LAHF.htm
- https://cs.lmu.edu/~ray/notes/nasmtutorial/
- https://nasm.us/docs.php